



In a previous article, we presented the Data Lake, a repository for structured and unstructured data, which represents the state-of-the-art architecture for Data Analytics thanks to its flexibility, agility and performance.
This kind of solution, despite being the best choice if you need to store data in different formats and to conduct Advanced Analytics such as clustering or classification tasks, often requires overcoming different challenges compared to traditional Business Intelligence architectures as Data Warehouses.
Generally speaking, the Data Lake needs more data expertise and a careful governance to prevent it from turning into a “Data Swamp” where information is useless or irremediably corrupted.
Hence, we should employ a technology that allows us to handle these issues and solve our problems: Databricks Delta.
What is Databricks Delta?
Launched in 2017, Databricks Delta is defined as an “unified data management system to simplify large-scale data management”[1], or in other words, a technology aimed at facilitating Big Data handling.

Source: Databricks.com
Databricks Delta is based on Delta Lake, an open-source Spark format to store data on a Data Lake layer (which could be Azure Data Lake or Amazon S3 for example). Delta ensures ACID transactions (Atomic, Consistent, Isolated and Durable) and at the same time the ability to execute writing and reading operations without impacting performances.
By leveraging the computing power of Apache Spark, Delta Lake also guarantees the possibility for many users to read and write a table at the same time. To always display the updated version of the table, Delta Lake uses a transaction log, in which every change made by a user is carefully tracked.
When a user reads or manipulates a table, Spark automatically check in the transaction log if changes have been made in the meantime and updates the table with its latest version. In this way, we can be sure that the latest version of the table will always be properly synchronized and that possible conflicting changes made by users will be avoided.
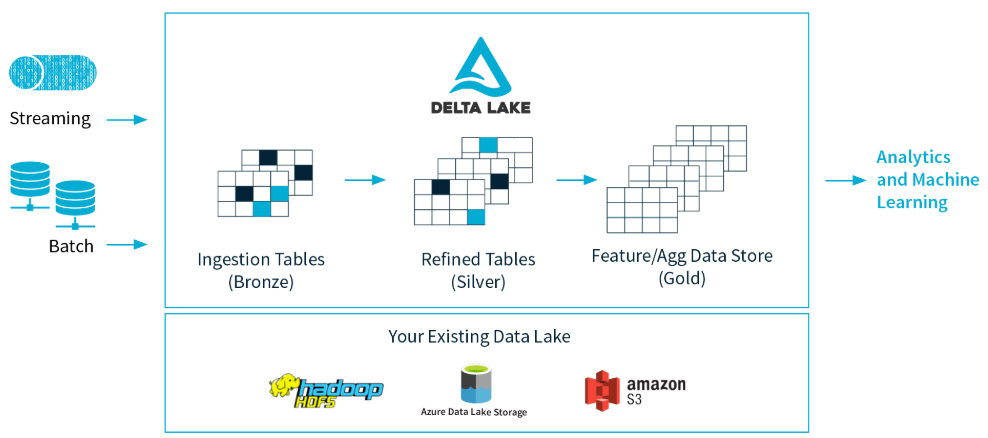
Source: Databricks.com
What are the benefits of using Databricks Delta for your Data Lake?
As we have already mentioned, implementing a Data Lake is not an easy task, and there are several challenges that should be addressed if we want to leverage the real power of this architecture.
In this regard, the Delta Lake format provided by Databricks may represent the winning choice in most circumstances.
Let’s take a look at some of its benefits:
Metadata Management
The Data Lake is a repository suited for storing data with different structures. We thus can retain in our Data Lake our structured data, as those coming from ERP or CRM, and unstructured data such as videos, images, tweets or documents extracted from the web. With highly heterogeneous data types is sometimes difficult to keep track of the metadata for every transformational layer that is present in our Data Lake. This problem may be solved by Databricks Delta, which allows the users to easily check for metadata in the transaction log at every step, making debugging and troubleshooting way more simple.
Data Quality
Let’s imagine that an ETL (Extract, Transform and Load) operation on several Terabytes of data irremediably fails to complete. We can therefore be in a situation in which our tables have only be partially written, corrupting our data and hampering the Data Quality of our system.
This situation won’t occur with Delta Lake, which guarantees ACID transactions, that ensure either the complete success or the shutdown of a writing operation. In this way, the execution of partial writing operation is impossible.
Data Consistency
With Data Consistency we are referring to the absence of conflicts between data. Take a bank account for example: the end-of-month balance must equal the sum of active and passive movements and the final balance of the previous month. This means that accounting records must be coherent to ensure this equation. However, is not uncommon for developers to employ different business logics when designing data pipelines for ETL on partitions (batch pipeline) or continuous streams of data (streaming pipelines). This phenomenon may also result in inconsistency problems due to the different logics and technologies employed in different scenarios. With Delta Lake we can use the same functions for batch and streaming pipelines and we can guarantee that business logics changes will be automatically incorporated in the Data Lake in a consistent way. Moreover, with Delta we can execute many reading and writing operations at the same time without compromising Data Consistency.
Data Versioning
Imagine having a Data Lake available for your Predictive Analytics experiments. In such a context, it’s likely that data undergoes several transformations, every time Data Scientists need to change data parameters for their experiments. Typically, if we want to keep the previous version of our data we need to make a copy every time we are changing a parameter for an experiment. This process, when it comes to Big Data, could definitely be a problem.
In Databricks Delta we can solve this issue through Data Versioning, a feature of Delta Lake that enables users to access to every version of a table through the transaction log, without having to make a “physical” copy of the dataset.
Furthermore, this feature could be extremely useful to fix the errors made in updates or insert operations, or to simply restore the previous version of the table after a delete operation.
Schema Enforcement e Schema Evolution
When talking about Data Lake its flexibility is often cited as one of its main advantages. However, we should remember that adaptability to changes it’s not always automatic but has to be properly arranged. With data sources that can change very quickly it’s necessary to prevent writing operations that generate incompatibility problems and corrupt data. In this regard, Delta Lake employs the so-called “Schema Enforcement” that verifies, before every writing operation, that new data is compatible with the target table schema, raising an exception and stopping the operation (avoiding partial writings) whenever there is a schema mismatch. For example, if we try to add an unexpected column to the existing table, the schema enforcement will block the writing, ensuring the consistency of the original schema.
At the same time, it may be useful to modify the existing schema every time there are changes in data. This is possible thanks to the “Schema Evolution” feature, which allows to easily modify the original schema to store data in the new format, without needing to recreate the table.
In conclusion, we can ultimately state that thanks to the abovementioned characteristics, Databricks Delta represents the winning choice for every company that needs to build a new Data Lake or to update its existing one, whether it is on-prem or cloud-based.
If you need further information or you’re looking for a specific advice for your company do not hesitate to contact us.
Read more:
- How to implement an effective Business Intelligence
- The best data infrastructure for your company: Data Warehouse vs. Data Lake
- 5 Steps to boost your company with Artificial Intelligence
[1] Armbrust, Chambers and Zaharia (2017). Databricks Delta: A Unified Data Management System for Real-time Big Data. Databricks blog.
Comments are closed.