



In the article “From business intelligence to predictive analytics systems” we talked of the evolution of the data analysis processes, describing an evolutionary path that led from performing simple queries on relational tables to business intelligence (BI) systems and from the latter to the use of predictive analytics. In this article we will instead discuss a further step towards innovative predictive analytics techniques, which are called prescriptive analytics.
If, instead of drawing a timeline as in the previous article, we examine the analysis techniques that are available and the output they produce, we can classify them into three categories:
- The descriptive techniques (descriptive analytics)
- The predictive techniques (Predictive Analytics)
- The prescriptive techniques (prescriptive analytics)
Sommario
Descriptive Analytics
When we think of Business Intelligence, the components and the output of the system itself fall under the descriptive analysis category. Through the data warehouse, the OLAP engines, and the reporting tools, from the easiest to the most complicated, what we do is analyze past data, categorizing it, filtering it, aggregating it, and applying mathematical or statistical functions to it, purely descriptive (sums, averages, variances, etc.). With OLAP engines you can easily perform slicing, dicing, drill-down, drill-up, and drill-across operations but they are still analysis that describe the past.
Predictive Analytics
Predictive techniques, instead use the past to have insights about the future. These are data mining techniques, which use methods of statistical analysis and machine learning as well as data modelling, preparation, and querying typical of database systems. We have to be clear in that the techniques of predictive analytics do not tell us what will happen in the future but only what could happen with a certain degree of probability.
Examples of predictive analytics applied to business can be:
- Churn Analysis. This involves analyzing the customer pool to determine which customers have a high probability of passing to the competition in order to intervene early and prevent their migration.
- Searching for anomalies. In this case the machine learning algorithms are able to identify abnormal situations, such as may fraudulent use of credit cards or insurance fraud.
- Cross Selling/Up Selling. The predictive techniques can be employed to determine which customers are most likely to buy a particular product, giving the company the opportunity to target a very specific group of potential buyers.
The main predictive analytics algorithms can be categorized into:
- Classification algorithms: these allow users to assign an object to a category. An example of classification problems is the identification of “churners”; in this case the categories between which to divide the customers is that of churners and that of loyal customers.
- Clustering algorithms: these algorithms group homogeneous elements in a data set. Clustering techniques are based on units related to the similarity between these elements.
- Frequent pattern mining: with these algorithms it is possible to identify sets of recurring elements even in very large datasets.
Prescriptive Analytics
We can now describe prescriptive analytics. It is an innovative concept (although the term first appeared in 2003) and it is based on predictive analytics yet it goes further by providing real rules directly applicable to the business. The consequence of this is the ability of the prescriptive model to enable decision makers to take immediate action, based on probabilistic forecasts and especially on clear and comprehensible rules that come from the model itself. Another important aspect of the prescriptive analytics models is their ability to analyze the feedback coming from using the rules, in order to take the actions carried out and their effects on the results into account.
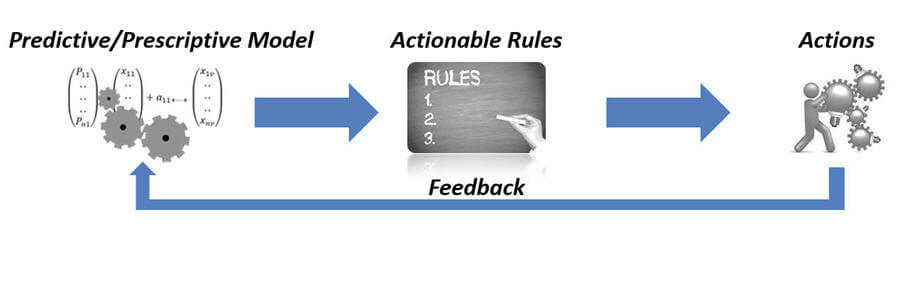
As already mentioned above, the prescriptive analytics models also belong to predictive analytics but they add to the latter the ability to explain the reasons behind a certain event: predictive models tell us what is likely to occur while the prescriptive models will explain the reasons (through a set of rules).
As we know, predictions are not valid forever and therefore the clues the model provides should leave enough time to act or they would end up being of little use during the decision-making and implementation process. If the rules produced by the model are simple and easy to interpret, then the time necessary for the action to take place will be short, allowing decision makers to fit in into the time frame of the prediction’s validity. We can now ask ourselves what are the algorithms that, in addition to generating a prediction, create rules that are immediately usable. These are three classes of algorithms:
- Decision trees
- Fuzzy Rule-Based System
- Switching Neural Networks (Logic Learning Machine)
Other systems such as, for example, Neural Networks or Support Vector Machines, despite being effective from the point of view of accuracy, specificity, and sensitivity of the model, are black-box machines, i.e. they do not provide any insight into how they reach a certain prediction.
Decision trees are simple to use but do not have a particularly brilliant predictive performance yet they are widely used (perhaps because they are one of the few systems that can produce rules) and implemented in many data mining tools. Fuzzy systems are the best from the predictive viewpoint but are not very common. The last algorithm, Switching Neural Networks, is implemented only in one machine learning tool – Rulex ( www.rulexinc.com ) – and presents a very high predictive ability.
We will discuss the three algorithms in detail in future articles.
Bibliography
Basu, A. T. A. N. U. (2013). Five pillars of prescriptive analytics success. Analytics Magazine.
Bertolucci, J. (April 15, 2013). Prescriptive Analytics and Data: Next Big Thing? InformationWeek.
Riza, Bergmeir, Herrera, Benìtez, 2015 , Fuzzy Rule-Based Systems for Classification and Regression in R – Journal of Statistical Software, Vol 65, Issue 6.
Muselli M. 2006 “Switching Neural Networks: A new connectionist model for classification”. WIRN 2005 and NAIS 2005, Lecture Notes on Computer Science
Comments are closed.