


Describing the 3Vs of Big Data
Big data is available in large volumes, it has unstructured formats and heterogeneous features, and are often produced in extreme speed: factors that identify them are therefore primarily Volume, Variety, Velocity.
Sommario
Let’s analyze these three parameters better:
Volume
Equivalent to the quantity of big data, regardless of whether they have been generated by the users or they have been automatically generated by machines. Big data like bank transactions and movements in the financial markets naturally assume mammoth values that cannot in any way be managed by traditional database tools. We can consider the volume of data generated by a company in terms of terabytes or petabytes.
Variety
Is the second characteristic of big data, and it is linked to the diversity of formats and, often, to the absence of a structure represented through a table in a relational database. The variety of big data is also due to its lack of structure: various types of documents (txt, csv, PDF, Word, Excel, etc.), Blog posts, comments on social networks or on micro-blogging platforms such as Twitter are included. Big data is also in various sources: part of it is automatically generated by machines, such as data from sensors or from access logs to a website or that regarding the traffic on a router, while other data is generated by web users.
Velocity
Is the speed with which new data becomes available. It is the third identifying feature of big data, and specifically in relation to this parameter does big data require the use of tools to ensure its proper storage. Among the technologies that can manage “high speed” data are the historian databases (for industrial automation) and those called streaming data or complex event processing (CEP) such as Microsoft StreamInsight, a framework for application development of complex event processing that allows you to monitor multiple sources of data, analyzing the latter incrementally and with low latency. CEP applications are applied successfully in the industrial, scientific, and financial area as well as that related to the analysis of web-generated events.
To date, Big Data can be characterized by three other discriminating factors:
- variability: una caratteristica riferita alla possibile inconsistenza dei dati analizzati;
- complexity: that increases in direct proportion to the size of the dataset;
- truth: related to the informative value that can be extracted from the data.
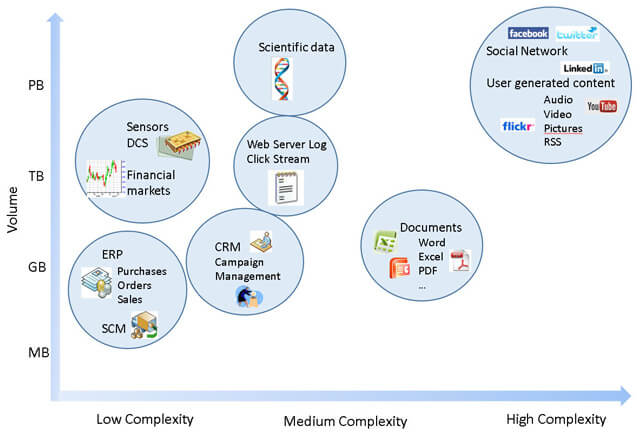
Wanting, however, to represent in a graph the universe of available data we can use, as a dimension of analysis, the parameters of volume and complexity:
Comments are closed.